美術館をGroverのアルゴリズムで解く
数独を一応解けるようになったので、 今度は美術館(Akari/Light Up)を解く。
4x4サイズの例題。

美術館のルールはこちらから。
パズル通信ニコリ vol.95より
- 盤面のいくつかの白マスに白丸(照明)を書き込みます
- 盤面の数字は、その数字の入っているマスにタテヨコに隣り合うマスのうち、照明が書かれるマスの数を表します
- 照明はそのマスから上下左右それぞれに、壁または黒マスにぶつかるまで直進できる範囲のマスを照らします
- 照明が照らす範囲に他の照明が含まれてはいけません
- どの照明にも照らされない白マスがあってはいけません
ルール1について、 各白マスに量子ビットを割り当て、そのビットの状態で照明を配置するかどうかを表現する(0状態:照明配置しない、1状態:照明配置する)。
今回はルール2を初期状態として処理し、 ルール3-5をオラクルで処理することにする。
ルール2について
条件を満たす照明の配置の候補を前処理として探して、 それらに対応する量子状態を等重み同位相で重ね合わせる。
例えば下記のような配置の場合を考える。

このとき、「2」のマスの周りの白マスの状態は$ \ket{q _ 0 q _ 1 q _ 2 q _ 3} $で表現できて、 ルール2を満たす配置は下記のようになる。
$$
% \require{physics}
\ket{q_0 q_1 q_2 q_3} = \frac1{\sqrt{6}}\qty(
\ket{1100} + \ket{1010} + \ket{1001} +
\ket{0110} + \ket{0101} + \ket{0011}
)
$$
同様に、「1」のマスの周りの白マスの状態は$ \ket{q _ 4 q _ 5 q _ 6} $で表現できて、 ルール2を満たす配置は下記のようになる。
$$
\ket{q_4 q_5 q_6} = \frac1{\sqrt{3}}\qty(
\ket{100} + \ket{010} + \ket{001}
)
$$
一方、例えば下記のように数字マスに隣接する白マスが他の数字マスにも隣接している場合、 白マスには両方の数字マスの条件が課される。

具体的には、$ q _ 1, q _ 4 $の白マスには、「2」のマスの条件が課せられ、同時に「1」のマスの条件が課せられる。 「2」のマスの条件のみの場合は$ q _ 0 q _ 1 q _ 2 q _ 4 $の状態として1100, 1010, 1001, 0110, 0101, 0011が許されるが、 このうち0101は「1」のマスの条件を満たさないため、この状態は取り除く必要がある。 このため、「1」「2」のマスの周りの白マスはまとめて取り扱う必要があり、 ルール2を満たす配置は下記のようになる。
$$
\ket{q_0 q_1 q_2 q_3 q_4 q_5} = \frac1{\sqrt{6}}\qty(
\ket{110000} + \ket{101100} + \ket{101001} + \ket{100010} +
\ket{011000} + \ket{001010}
)
$$
これらを考慮し、
まとめて取り扱うべきマスのリストgridsと、そのマスに対して取りうる状態のリストstatesとを含むクラスCandidateを作り、
数字マスの条件はCandidateのリストとして取り扱う。
ルール3-5について
各白マスに対して条件を満たすかをチェックする。 下記のように、対象のマスをq0、そのマスから「上下左右それぞれに壁または黒マスにぶつかるまで直進できる範囲」のマスをq1,q2,…とする。

このとき、ルール3-5は、全白マスで次の条件が成立すればよいことになる。 - q0に照明が配置される場合には、q1,q2,…のいずれにも照明が配置されない。 - q0に照明が配置されない場合には、q1,q2,…の少なくともいずれかに照明が配置される。
これは、「q0に照明が配置される」をA、「q1,q2,…のいずれにも照明が配置されない」をBとすると、下記のように表される。
$$
\qty(A \to B) \land \qty(\neg A \to \neg B)
$$
ここで、$ P \to Q = \neg P \lor \qty(P \land Q) $なので、上記の条件は次のように書き換えられる。
$$
\begin{align*}
&
\qty(A \to B) \land \qty(\neg A \to \neg B) \\
=&
\qty(\neg A \lor \qty( A \land B)) \land
\qty( A \lor \qty(\neg A \land \neg B)) \\
=&
\underbrace{
\qty(\neg A \land A )
}_{=\mathrm{False}}
\lor
\qty(\neg A \land \qty(\neg A \land \neg B)) \lor
\qty(\qty( A \land B) \land A ) \lor
\underbrace{
\qty(\qty( A \land B) \land \qty(\neg A \land \neg B))
}_{=\mathrm{False}} \\
=&
\qty(\neg A \land \neg B) \lor
\qty( A \land B) \\
=&
\qty(\neg A \land \neg B) \oplus
\qty(A \land B)
\end{align*}
$$
ここで、最後の等号で、ORの前後の項は両立しないのでORをXORとした。
複数の項をXORで関係づけた条件は、 それぞれの項に対応する条件付きXゲートを標的ビットに単純に続けて作用させればよい。 条件B(q1,q2,…のいずれにも照明が配置されない)は、 q1,q2,…を反転制御ビットとしたマルチ制御Xゲート(条件Bに対応する条件付きXゲート)で実現できる。 このため、第2項は、q0を制御ビット、q1,q2,…を反転制御ビットとしたマルチ制御Xゲートで実現できる。
条件Bの否定は、条件Bに対応する条件付きXゲートと標的ビットへのXゲート(NOTゲート)で実現できる。 このため、第1項は、 q0を反転制御ビットとした制御Xゲートと、 q0,q1,q2,…を反転制御ビットとしたマルチ制御Xゲートで実現できる。
まとめると、次の量子回路で1つの白マスに対するオラクルを実現できる。

実装
盤面(board)などの情報を詰め込んだAkariクラスを作る。Akariクラスは下記の情報などを持っている。
- 空きマス(grid)の行列番号のリスト
blanks - 数字マスの行列番号のリスト
nums - 空きマスに対応する状態の候補(
Candidate)のリストcands - 各空きマスについて、「そのマスから上下左右それぞれに壁または黒マスにぶつかるまで直進できる範囲」のマスのリストを対応させるdict
rngs - 空きマスにレジスタを対応させるdict(量子レジスタ
qregs、古典レジスタcregs)
Candidateクラスは次の情報を持っている。
- 共通する白マスに隣接する数字マスの周りの白マスとしてまとめて取り扱うべきマス(の行列番号)のリスト
grids - それらのマスに対して取りうる状態のリスト
states
import itertools import functools import numpy as np from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister from qiskit_aer import AerSimulator from qiskit import transpile from qiskit.quantum_info import Statevector
class Candidate: def __init__(self, grids, states): self.grids = grids self.states = states def __str__(self): return str(self.grids)+str(self.states) def get_common(self, cd): # Return list of grids that are in common with cd return list(set(self.grids) & set(cd.grids)) def merge(self, cd, common): # Merge Candidate cd into self grd1 = list(filter(lambda g: not g in common, self.grids)) # self grids NOT common to cd grd2 = list(filter(lambda g: not g in common, cd.grids)) # cd grids NOT common to self grids = common + grd1 + grd2 states = [] for st1,st2 in itertools.product(self.states, cd.states): match = True for g in common: i = self.grids.index(g) j = cd.grids.index(g) match = match and st1[i] == st2[j] if match: # Exclude inconsistent states for common grids st = list(map(lambda g: st1[self.grids.index(g)], common)) st += list(map(lambda g: st1[self.grids.index(g)], grd1)) st += list(map(lambda g: st2[cd.grids.index(g)], grd2)) states.append(''.join(st)) self.grids = grids self.states = states
class Akari: def __init__(self, board): # board : Akari board # _ : blank grid (white cell) # * : wall grid (black cell) # 0-4: number grid (black cell with number) # @ : light _board = [] for line in filter(lambda x: x, map(str.strip, board.split("\n"))): _grids = [] for grid in line.split(): _grids.append(grid) _board.append(_grids) self.board=_board # 2D array (list of lists for each row) self.nrow=len(self.board) # number of rows self.ncol=len(self.board[0]) # number of columns self.blanks = self.get_blanks() # list of blank grids self.nums = self.get_nums() # list of number grids self.cands = self.get_cands(self.blanks, self.nums) # list of candidates for the state corresponding to blank grids self.rngs = self.get_rngs(self.blanks) # Range that can go straight from each blank grid self.qregs = self.get_qregs(self.blanks) # QuantumRegisters for each blank grid self.cregs = self.get_cregs(self.blanks) # ClassicalRegisters for each blank grid def __str__(self): return self.write_board() def __getitem__(self, grid): return self.board[grid[0]][grid[1]] def write_board(self, answer=None): s = "" for r in range(self.nrow): for c in range(self.ncol): if answer and self.is_blank(r,c): a = answer.get((r,c)) if a == "1": s += " @" else: s += " _" else: s += f" {self[r,c]}" s += "\n" return s[:-1] # remove trailing newline def is_blank(self,r,c): return self[r,c] == "_" def is_num(self,r,c): return self[r,c] in {"0", "1", "2", "3", "4"} def is_wall(self,r,c): return not ( r in range(self.nrow) and c in range(self.ncol) and self.is_blank(r,c)) def get_blanks(self): return list(filter( lambda g: self.is_blank(*g), (itertools.product(range(self.nrow), range(self.ncol)) ))) def get_nums(self): return list(filter( lambda g: self.is_num(*g), (itertools.product(range(self.nrow), range(self.ncol)) ))) def get_cands(self, blanks=None, nums=None): if blanks is None: blanks = self.get_blanks() if nums is None: nums = self.get_nums() pre_cands = list( map(lambda g: Candidate([g],["0", "1"]), blanks) ) cands = [] for numg in nums: r,c = numg adjacent = list(filter(lambda g: not self.is_wall(*g),[ (r-1,c), (r,c-1), (r,c+1), (r+1,c), ])) n = int(self[r,c]) nbit = len(adjacent) states = list(filter(lambda s:s.count("1") == n, # 2. narrow down the states to meet number grid condition map(lambda x:f"{x:0{nbit}b}", range(2**nbit)) # 1. express possible states of adjacent grids as binary numbers )) pre_cands.append(Candidate(adjacent, states)) # merge candidates with overlapping blank grids while pre_cands: idx_merged = [] cd0 = pre_cands.pop(-1) for cd1 in pre_cands: common = cd0.get_common(cd1) if common: cd0.merge(cd1, common) idx_merged.append(cd1) pre_cands = list(filter( lambda cd: not cd in idx_merged, pre_cands)) if idx_merged: pre_cands.append(cd0) else: cands.append(cd0) return cands def get_rngs(self, blanks=None): if blanks is None: blanks = self.get_blanks() rngs = dict() for g in blanks: rng = [] # left for dc in range(1,self.ncol): gx = (g[0], g[1]-dc) if self.is_wall(*gx): break rng.append(gx) # right for dc in range(1,self.ncol): gx = (g[0], g[1]+dc) if self.is_wall(*gx): break rng.append(gx) # up for dr in range(1,self.nrow): gx = (g[0]-dr, g[1]) if self.is_wall(*gx): break rng.append(gx) # down for dr in range(1,self.nrow): gx = (g[0]+dr, g[1]) if self.is_wall(*gx): break rng.append(gx) rngs[g] = rng return rngs def get_qregs(self, blanks=None): if blanks is None: blanks = self.get_blanks() qregs = dict() for g in blanks: qregs[g]=QuantumRegister(1, f"q{g[0]}{g[1]}") return qregs def get_cregs(self, blanks=None): if blanks is None: blanks = self.get_blanks() cregs = dict() for g in blanks: cregs[g]=ClassicalRegister(1, f"c{g[0]}{g[1]}") return cregs # test board = """ _ _ _ * _ 2 _ _ _ _ 3 _ 1 _ _ _ """ akari = Akari(board) print(akari) print("number grids:") for g in akari.nums: print(g) print("blank grids and corresponding ranges:") for g in akari.blanks: print(g, akari.rngs[g]) print("candidates:") for cd in akari.cands: print(cd)
_ _ _ * _ 2 _ _ _ _ 3 _ 1 _ _ _ number grids: (1, 1) (2, 2) (3, 0) blank grids and corresponding ranges: (0, 0) [(0, 1), (0, 2), (1, 0), (2, 0)] (0, 1) [(0, 0), (0, 2)] (0, 2) [(0, 1), (0, 0), (1, 2)] (1, 0) [(0, 0), (2, 0)] (1, 2) [(1, 3), (0, 2)] (1, 3) [(1, 2), (2, 3), (3, 3)] (2, 0) [(2, 1), (1, 0), (0, 0)] (2, 1) [(2, 0), (3, 1)] (2, 3) [(1, 3), (3, 3)] (3, 1) [(3, 2), (3, 3), (2, 1)] (3, 2) [(3, 1), (3, 3)] (3, 3) [(3, 2), (3, 1), (2, 3), (1, 3)] candidates: [(3, 1), (2, 0)]['10', '01'] [(1, 0), (0, 1), (1, 2), (2, 1), (3, 2), (2, 3)]['100111', '010111', '101011', '011011', '001110', '001101'] [(3, 3)]['0', '1'] [(1, 3)]['0', '1'] [(0, 2)]['0', '1'] [(0, 0)]['0', '1']
次に、マス毎の初期化を行うゲートを作る。
数独と同様に、マルチ制御y回転ゲートをまず作り、それを使って各マスを各Candidateに従って初期化するゲートを作る。
grids_initの引数statesには、候補となる状態の二進数表現を文字列のリストで入れる。
def multi_ctrl_ry(bctrl, theta, to_gate=True): nctrl = len(bctrl) qrc = QuantumRegister(nctrl,"ctrl") qrt = QuantumRegister(1,"tgt") qc = QuantumCircuit(qrc, qrt) qc.sdg(qrt) qc.h(qrt) for i,b in enumerate(bctrl): if b == "0": qc.x(qrc[i]) qc.mcp(theta,qrc,qrt) # multi-contorolled phase gate qc.mcp(-theta/2, qrc[:-1], qrc[-1]) # phase correction for i,b in enumerate(bctrl): if b == "0": qc.x(qrc[i]) qc.h(qrt) qc.s(qrt) return qc.to_gate(label=f"mcry{bctrl}\n{theta:0.3}") if to_gate else qc
def grids_init(states, to_gate=True): nbit = len(states[0]) qc = QuantumCircuit(nbit) qbits = qc.qubits nprev = len(states) def devide(key, lst): if not lst: return ntot = len(lst) nb = len(key) k0 = key + "0" k1 = key + "1" l0 = list(filter(lambda x: x.startswith(k0), lst)) l1 = list(filter(lambda x: x.startswith(k1), lst)) th = 2 * np.acos(np.sqrt(len(l0)/ntot)) if nb == 0: qc.ry(th, qbits[0]) elif nb == 1: if key == "0": qc.x(qbits[0]) qc.cry(th, qbits[0], qbits[1]) if key == "0": qc.x(qbits[0]) else: qc.append(multi_ctrl_ry(key, th), qbits[:nb+1]) if nb < nbit-1: devide(k0, l0) devide(k1, l1) devide("", states) return qc.to_gate(label=r"$U_i$") if to_gate else qc
次に、上記のCandidateオブジェクトごとの初期化ゲートを使って、
入力量子レジスタ全体を初期化するゲートを作り、それを使って拡散演算子$ P _ {s _ \perp} $を作る。
def initialize(akari, to_gate=True): qc=QuantumCircuit() for g in akari.blanks: qc.add_register(akari.qregs[g]) for cd in akari.cands: qregs = list(map(lambda g: akari.qregs[g] ,cd.grids)) qc.append(grids_init(cd.states), qregs) return qc.to_gate(label=r"$U_s$") if to_gate else qc initialize(akari, to_gate=False).draw(output='mpl')

def diffuse(akari, Us, to_gate=True): qc=QuantumCircuit() qr = [] for g in akari.blanks: qc.add_register(akari.qregs[g]) qr += akari.qregs[g][:] Usdg = Us.inverse() Usdg.name = r"$U_s^\dagger$" qc.append(Usdg, qr) qc.x(qr) qc.h(qr[-1]) qc.mcx(qr[:-1],qr[-1]) qc.h(qr[-1]) qc.x(qr) qc.append(Us, qr) return qc.to_gate(label=r"$P_{s_\perp}$") if to_gate else qc
続いて、オラクル$ P _ \omega $を作る。
各マスの条件に対応する条件付きXゲートを作る。
照明が照らす範囲のマス数をn_gridに入れる。
def grid_conditional(n_grid, to_gate=True): qrc = QuantumRegister(1, 'c') # register for center blank grid qrx = QuantumRegister(n_grid, 'x') # register for grids in lighting-up range qrt = QuantumRegister(1, 'tgt') # register for target bit qc=QuantumCircuit(qrc,qrx,qrt) qc.x(qrc) qc.x(qrx) qc.cx(qrc,qrt) qc.mcx(qrc[:]+qrx[:],qrt) qc.x(qrc) qc.mcx(qrc[:]+qrx[:],qrt) qc.x(qrx) return qc.to_gate(label=r"$N$") if to_gate else qc grid_conditional(4, to_gate=False).draw(output='mpl')

def oracle(akari, to_gate=True): qc=QuantumCircuit() # input registers for g in akari.blanks: qc.add_register(akari.qregs[g]) # ancilla qra = QuantumRegister(1,"anc") qc.add_register(qra) # target qrt = QuantumRegister(1,"tgt") qc.add_register(qrt) conditions = [] for g in akari.blanks: gc = grid_conditional(len(akari.rngs[g])) qrx = akari.qregs[g][:] for gx in akari.rngs[g]: qrx += akari.qregs[gx][:] conditions.append((gc, qrx)) mc = len(conditions) th = np.pi/(2**(mc-1)) def append_gates(m): if m == 1: qc.append(conditions[m-1][0], conditions[m-1][1]+qra[:]) qc.cp(th, qra, qrt) else: append_gates(m-1) qc.append(conditions[m-1][0], conditions[m-1][1]+qra[:]) qc.cp(-th, qra, qrt) append_gates(m-1) qc.h(qrt) append_gates(mc) qc.append(conditions[mc-1][0], conditions[mc-1][1]+qra[:]) qc.h(qrt) return qc.to_gate(label=r"$P_\omega$") if to_gate else qc
拡散演算子とオラクルから、Grover回転のゲートを作る。
def rotation(akari, diffuse_gate, oracle_gate, to_gate=True): qc=QuantumCircuit() qr = [] # input registers for g in akari.blanks: qc.add_register(akari.qregs[g]) qr += akari.qregs[g][:] # ancilla qra = QuantumRegister(1,"anc") qc.add_register(qra) # target qrt = QuantumRegister(1,"tgt") qc.add_register(qrt) qc.append(oracle_gate, qr[:]+qra[:]+qrt[:]) qc.append(diffuse_gate, qr[:]) return qc.to_gate(label=r"$G$") if to_gate else qc
以上の処理をまとめて、Akariオブジェクトを入力としてGroverのアルゴリズムで数独を解く量子回路を返す関数を作る。
def grover_akari(akari, eps=0.05, mmax=100): qc=QuantumCircuit() qr = [] cr = [] # input registers for g in akari.blanks: qc.add_register(akari.qregs[g]) qc.add_register(akari.cregs[g]) qr += akari.qregs[g][:] cr += akari.cregs[g][:] # ancilla qra = QuantumRegister(1,"anc") qc.add_register(qra) # target qrt = QuantumRegister(1,"tgt") qc.add_register(qrt) # gates Us = initialize(akari) Ps = diffuse(akari, Us) Po = oracle(akari) Gr = rotation(akari, Ps, Po) #initialization qc.append(Us, qr) # make target qubit into |-> state qc.h(qrt) qc.z(qrt) # Grover rotation nstate = functools.reduce( lambda x,y: x*y, map(lambda cd: len(cd.states), akari.cands) ) mrep = 1 for m in range(1,mmax): p = np.cos((2*m+1)/np.sqrt(nstate))**2 if p < eps: mrep = m prob = p break rot = Gr.repeat(mrep) rot.name=f"Gx{mrep}" qc.append(rot, qr[:]+qra[:]+qrt[:]) # measurement qc.measure(qr[:], cr[:]) return qc # test board = """ _ _ _ * _ 2 _ _ _ _ 3 _ 1 _ _ _ """ akari = Akari(board) grover_akari(akari).draw(output='mpl')

AerSimulatorで実行。
countの降順で解を順位max_rankまで表示するようにした。
def run_grover_akari(akari, qc, backend, shots=1024): tqc = transpile(qc, backend) job = backend.run(tqc, shots=shots) rst = job.result() counts = rst.get_counts() # output print("-- akari problem --") print(akari) print() rank = 0 max_rank = 6 print("-- answers --") for k,v in sorted(rst.get_counts().items(), key=lambda x:x[1], reverse=True): rank += 1 if rank > max_rank: break answer = dict() for g, q in zip(akari.blanks, k.split()[::-1]): answer[g] = q print(akari.write_board(answer)) print(f"rank: {rank} / count: {v}\n") backend = AerSimulator() qc = grover_akari(akari) run_grover_akari(akari, qc, backend)
-- akari problem -- _ _ _ * _ 2 _ _ _ _ 3 _ 1 _ _ _ -- answers -- _ @ _ * _ 2 @ _ @ _ 3 @ 1 _ @ _ rank: 1 / count: 981 _ @ @ * _ 2 _ _ @ @ 3 @ 1 _ @ @ rank: 2 / count: 3 _ _ _ * _ 2 @ @ @ @ 3 @ 1 _ _ _ rank: 3 / count: 2 @ _ @ * @ 2 _ _ @ @ 3 @ 1 _ @ @ rank: 4 / count: 2 @ _ @ * @ 2 @ @ @ _ 3 @ 1 _ @ @ rank: 5 / count: 2 @ _ _ * @ 2 @ @ _ _ 3 @ 1 @ @ _ rank: 6 / count: 2
4x4の他の問題。

board = """ _ 2 _ _ _ _ _ * 1 _ _ _ _ _ 0 _ """ akari = Akari(board) qc = grover_akari(akari) run_grover_akari(akari, qc, backend)
-- akari problem -- _ 2 _ _ _ _ _ * 1 _ _ _ _ _ 0 _ -- answers -- @ 2 _ @ _ @ _ * 1 _ _ @ @ _ 0 _ rank: 1 / count: 1024
ということで、美術館の問題にも対応するようにできた。
4x4より大きいサイズの数独をGroverのアルゴリズムで解く
前にやったもの では量子ビット数の制限で(シミュレータ上で)解ける問題が少なかったので、 オラクルの補助量子ビットを減らすように マルチAND制御ゲートを使って改造した。 また、初期状態を構成するゲートを一般化して、 4x4より大きいものについても(一応)対応するようにした。
実装
大部分が同じなので、どんどん実装していく。 空きマス同士のペアに対応する補助量子ビットは不要なので、その部分は削除。
import itertools import functools import numpy as np from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister from qiskit_aer import AerSimulator from qiskit import transpile from qiskit.quantum_info import Statevector class Sudoku: def __init__(self, board, nrblk, ncblk): # board : sudoku board / _ : blank cell # nrblk : number of grids in each row in each block # ncblk : number of grids in each column in each block _board = [] for line in filter(lambda x: x, map(str.strip, board.split("\n"))): _grids = [] for grid in line.split(): _grids.append(grid) _board.append(_grids) self.board=_board # 2D array (list of lists for each row) self.nrblk=nrblk self.ncblk=ncblk self.nsize=nrblk * ncblk # number of grids in each line (row or column) in a board self.nbit=(self.nsize-1).bit_length() # bit number for grid variable self.blanks = self.get_blanks() # list of blank grids self.cands = self.get_cands(self.blanks) # list of candidate-values for each blank grids self.pairs = self.get_pairs(self.blanks) # list of pairs of blank grids which are in the same row / column / block self.qregs = self.get_qregs(self.blanks) # QuantumRegisters for each blank grid self.cregs = self.get_cregs(self.blanks) # ClassicalRegisters for each blank grid def __str__(self): return self.write_board() def __getitem__(self, grid): return self.board[grid[0]][grid[1]] def write_board(self, answer=None): hlb = "--" * self.ncblk + "-+" hl = "+" + hlb * self.nrblk + "\n" # holizontal line s = hl for r in range(self.nsize): s += "|" for c in range(self.nsize): if answer and self.is_blank(r,c): a = answer.get((r,c)) if a: s += f"{a:>2}" else: s += " _" else: s += f"{self[r,c]:>2}" if not (c+1) % self.ncblk: # vertical line (block boundary) s += " |" s += "\n" if not (r+1) % self.nrblk: # holizontal line (block boundary) s += hl return s[:-1] # remove trailing newline def is_blank(self,r,c): return self[r,c] == "_" def row_vals(self,r): return set(filter(lambda x: x != 0, (self[r,c] for c in range(self.nsize)))) def col_vals(self,c): return set(filter(lambda x: x != 0, (self[r,c] for r in range(self.nsize)))) def blk_vals(self,r,c): rb = r // self.nrblk cb = c // self.ncblk return set(filter(lambda x: x != 0, (self[ir,ic] for ir in range(rb*self.nrblk, (rb+1)*self.nrblk) for ic in range(cb*self.ncblk, (cb+1)*self.ncblk) ))) def same_block(self, g1, g2): return (g1[0] // self.nrblk == g2[0] // self.nrblk and g1[1] // self.ncblk == g2[1] // self.ncblk ) def get_blanks(self): return list(filter( lambda g: self.is_blank(*g), (itertools.product(range(self.nsize), repeat=2) ))) def get_cands(self, blanks=None): if blanks is None: blanks = self.get_blanks() cands = dict() for g in blanks: cands[g] = set(filter(lambda x: x not in self.row_vals(g[0]) and # row x not in self.col_vals(g[1]) and # column x not in self.blk_vals(*g), # block map(str, range(1,self.nsize+1)) )) return cands def get_pairs(self, blanks=None): if blanks is None: blanks = self.get_blanks() pairs = [] for g1,g2 in itertools.combinations(blanks, 2): if (g1[0] == g2[0] or # row g1[1] == g2[1] or # column self.same_block(g1,g2) ): # block pairs.append((g1,g2)) return pairs def get_qregs(self, blanks=None): if blanks is None: blanks = self.get_blanks() qregs = dict() for g in blanks: qregs[g]=QuantumRegister(self.nbit, f"q{g[0]}{g[1]}") return qregs def get_cregs(self, blanks=None): if blanks is None: blanks = self.get_blanks() cregs = dict() for g in blanks: cregs[g]=ClassicalRegister(self.nbit, f"c{g[0]}{g[1]}") return cregs
次に、マス毎の初期化を行うゲートを作る。 マルチ制御y回転ゲートをまず作る。
def multi_ctrl_ry(bctrl, theta, to_gate=True): nctrl = len(bctrl) qrc = QuantumRegister(nctrl,"ctrl") qrt = QuantumRegister(1,"tgt") qc = QuantumCircuit(qrc, qrt) qc.sdg(qrt) qc.h(qrt) for i,b in enumerate(reversed(bctrl)): if b == "0": qc.x(qrc[i]) qc.mcp(theta,qrc,qrt) # multi-contorolled phase gate qc.mcp(-theta/2, qrc[:-1], qrc[-1]) # phase correction for i,b in enumerate(reversed(bctrl)): if b == "0": qc.x(qrc[i]) qc.h(qrt) qc.s(qrt) return qc.to_gate(label=f"mcry{bctrl}\n{theta:0.3}") if to_gate else qc
次に、各マスを初期化するゲートを作る。
ここではゲートを作るだけなので、ビット数が同じなら違うレジスタを入れてもよい(はず)。
candには、1から始まる整数値の候補を文字列で入れる。
def grid_init(nbit, cand, to_gate=True): qc = QuantumCircuit(nbit) qbits = qc.qubits nprev = len(cand) def devide(key, lst): if not lst: return ntot = len(lst) nb = len(key) k0 = key + "0" k1 = key + "1" l0 = list(filter(lambda x: x.startswith(k0), lst)) l1 = list(filter(lambda x: x.startswith(k1), lst)) th = 2 * np.acos(np.sqrt(len(l0)/ntot)) if nb == 0: qc.ry(th, qbits[-1]) elif nb == 1: if key == "0": qc.x(qbits[-1]) qc.cry(th, qbits[-1], qbits[-2]) if key == "0": qc.x(qbits[-1]) else: qc.append(multi_ctrl_ry(key, th), qbits[-nb:]+qbits[-(nb+1):-nb]) if nb < nbit-1: devide(k0, l0) devide(k1, l1) devide("", list(map(lambda x : f"{int(x)-1:0{nbit}b}", cand))) return qc.to_gate(label=r"$U_i$") if to_gate else qc
次に、マス毎の初期化ゲートを使って、入力量子レジスタ全体を初期化するゲートを作り、それを使って拡散演算子$ P _ {s _ \perp} $を作る。
def initialize(sudoku, grid_init, to_gate=True): qc=QuantumCircuit() for g in sudoku.blanks: qc.add_register(sudoku.qregs[g]) qc.append(grid_init(sudoku.nbit, sudoku.cands[g]), sudoku.qregs[g]) return qc.to_gate(label=r"$U_s$") if to_gate else qc
def diffuse(sudoku, Us, to_gate=True): qc=QuantumCircuit() qr = [] for g in sudoku.blanks: qc.add_register(sudoku.qregs[g]) qr += sudoku.qregs[g][:] Usdg = Us.inverse() Usdg.name = r"$U_s^\dagger$" qc.append(Usdg, qr) qc.x(qr) qc.h(qr[-1]) qc.mcx(qr[:-1],qr[-1]) qc.h(qr[-1]) qc.x(qr) qc.append(Us, qr) return qc.to_gate(label=r"$P_{s_\perp}$") if to_gate else qc
続いて、オラクル$ P _ \omega $を作る。
2数が異なることを検出するゲートは、前に作ったものを流用する。
def neq(n, to_gate=True): # non-equality-conditional X gate with n-controll bit(s): # quantum gate which applies X-gate to the target qubit only when a != b, where a and b is n-bit variables qra = QuantumRegister(n, 'a') # register for 1st n-bit variable a qrb = QuantumRegister(n, 'b') # register for 2nd n-bit variable b qrt = QuantumRegister(1, 'tgt') # register for target bit qc=QuantumCircuit(qra,qrb,qrt) qc.x(qrb) for x in range(2**n): cb = [] for i,b in enumerate(format(x, f'0{n}b')[::-1]): if b == "1": cb.append(i) elif b == "0": cb.append(i+n) qc.mcx(cb,qrt) qc.x(qrb) qc.x(qrt) return qc.to_gate(label=r"$N$") if to_gate else qc
def oracle(sudoku, to_gate=True): qc=QuantumCircuit() # input registers for g in sudoku.blanks: qc.add_register(sudoku.qregs[g]) # ancilla qra = QuantumRegister(1,"anc") qc.add_register(qra) # target qrt = QuantumRegister(1,"tgt") qc.add_register(qrt) ne = neq(sudoku.nbit) conditions = [] for p in sudoku.pairs: g1, g2 = p conditions.append((ne, sudoku.qregs[g1][:]+sudoku.qregs[g2][:])) mc = len(conditions) th = np.pi/(2**(mc-1)) def append_gates(m): if m == 1: qc.append(conditions[m-1][0], conditions[m-1][1]+qra[:]) qc.cp(th, qra, qrt) else: append_gates(m-1) qc.append(conditions[m-1][0], conditions[m-1][1]+qra[:]) qc.cp(-th, qra, qrt) append_gates(m-1) qc.h(qrt) append_gates(mc) qc.append(conditions[mc-1][0], conditions[mc-1][1]+qra[:]) qc.h(qrt) return qc.to_gate(label=r"$P_\omega$") if to_gate else qc
拡散演算子とオラクルから、Grover回転のゲートを作る。
def rotation(sudoku, diffuse_gate, oracle_gate, to_gate=True): qc=QuantumCircuit() qr = [] # input registers for g in sudoku.blanks: qc.add_register(sudoku.qregs[g]) qr += sudoku.qregs[g][:] # ancilla qra = QuantumRegister(1,"anc") qc.add_register(qra) # target qrt = QuantumRegister(1,"tgt") qc.add_register(qrt) qc.append(oracle_gate, qr[:]+qra[:]+qrt[:]) qc.append(diffuse_gate, qr[:]) return qc.to_gate(label=r"$G$") if to_gate else qc
以上の処理をまとめて、Sudokuオブジェクトを入力としてGroverのアルゴリズムで数独を解く量子回路を返す関数を作る。
まずは、前回同様に4x4の空き6マス(7条件)問題でテスト。
初期状態の数はいずれも大きくないので、Grover回転は一回のみ掛けることにする(mmax=1)。
def grover_sudoku(sudoku, eps=0.05, mmax=100): qc=QuantumCircuit() qr = [] cr = [] # input registers for g in sudoku.blanks: qc.add_register(sudoku.qregs[g]) qc.add_register(sudoku.cregs[g]) qr += sudoku.qregs[g][:] cr += sudoku.cregs[g][:] # ancilla qra = QuantumRegister(1,"anc") qc.add_register(qra) # target qrt = QuantumRegister(1,"tgt") qc.add_register(qrt) # gates Us = initialize(sudoku, grid_init) Ps = diffuse(sudoku, Us) Po = oracle(sudoku) Gr = rotation(sudoku, Ps, Po) #initialization qc.append(Us, qr) # make target qubit into |-> state qc.h(qrt) qc.z(qrt) # Grover rotation nstate = functools.reduce( lambda x,y: x*y, map(len, sudoku.cands.values()) ) mrep = 1 for m in range(1,mmax): p = np.cos((2*m+1)/np.sqrt(nstate))**2 if p < eps: mrep = m prob = p break rot = Gr.repeat(mrep) rot.name=f"Gx{mrep}" qc.append(rot, qr[:]+qra[:]+qrt[:]) # measurement qc.measure(qr[:], cr[:]) return qc # test board = """ 1 2 3 4 _ _ _ 2 3 _ _ _ 2 1 4 3 """ sudoku = Sudoku(board, 2, 2) grover_sudoku(sudoku, mmax=1).draw(output='mpl')

AerSimulatorで実行。
countの降順で解を表示するようにした。
def run_grover_sudoku(sudoku, qc, backend, shots=1024): tqc = transpile(qc, backend) job = backend.run(tqc, shots=shots) rst = job.result() counts = rst.get_counts() # output print("-- sudoku problem --") print(sudoku) print() print("-- answers --") for k,v in sorted(rst.get_counts().items(), key=lambda x:x[1], reverse=True): answer = dict() for g, q in zip(sudoku.blanks, k.split()[::-1]): answer[g] = str(int(q, base=2)+1) print(sudoku.write_board(answer)) print(f"count: {v}\n") backend = AerSimulator() qc = grover_sudoku(sudoku, mmax=1) run_grover_sudoku(sudoku, qc, backend)
-- sudoku problem -- +-----+-----+ | 1 4 | 2 3 | | 2 3 | _ 4 | +-----+-----+ | 3 _ | _ _ | | 4 2 | _ _ | +-----+-----+ -- answers -- +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 4 2 | | 4 2 | 3 1 | +-----+-----+ count: 808 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 4 1 | | 4 2 | 1 1 | +-----+-----+ count: 37 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 1 2 | | 4 2 | 1 1 | +-----+-----+ count: 35 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 4 1 | | 4 2 | 3 1 | +-----+-----+ count: 31 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 4 2 | | 4 2 | 1 1 | +-----+-----+ count: 30 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 1 2 | | 4 2 | 3 1 | +-----+-----+ count: 29 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 1 1 | | 4 2 | 1 1 | +-----+-----+ count: 28 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 1 1 | | 4 2 | 3 1 | +-----+-----+ count: 26
4x4の空き6マス(10条件)問題。 この辺りまでは前回でも解けた。
board = """ _ _ _ 1 _ _ 2 3 _ 4 1 2 1 2 3 4 """ sudoku = Sudoku(board,2,2) qc = grover_sudoku(sudoku, mmax=1) run_grover_sudoku(sudoku, qc, backend)
-- sudoku problem -- +-----+-----+ | _ _ | _ 1 | | _ _ | 2 3 | +-----+-----+ | _ 4 | 1 2 | | 1 2 | 3 4 | +-----+-----+ -- answers -- +-----+-----+ | 2 3 | 4 1 | | 4 1 | 2 3 | +-----+-----+ | 3 4 | 1 2 | | 1 2 | 3 4 | +-----+-----+ count: 959 +-----+-----+ | 3 3 | 4 1 | | 4 1 | 2 3 | +-----+-----+ | 3 4 | 1 2 | | 1 2 | 3 4 | +-----+-----+ count: 36 +-----+-----+ | 4 3 | 4 1 | | 4 1 | 2 3 | +-----+-----+ | 3 4 | 1 2 | | 1 2 | 3 4 | +-----+-----+ count: 29
board = """ 1 4 2 3 2 3 _ 4 3 _ _ _ 4 2 _ _ """ sudoku = Sudoku(board,2,2) qc = grover_sudoku(sudoku, mmax=1) run_grover_sudoku(sudoku, qc, backend)
-- sudoku problem -- +-----+-----+ | 1 4 | 2 3 | | 2 3 | _ 4 | +-----+-----+ | 3 _ | _ _ | | 4 2 | _ _ | +-----+-----+ -- answers -- +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 4 2 | | 4 2 | 3 1 | +-----+-----+ count: 787 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 1 1 | | 4 2 | 3 1 | +-----+-----+ count: 41 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 1 2 | | 4 2 | 1 1 | +-----+-----+ count: 40 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 4 1 | | 4 2 | 3 1 | +-----+-----+ count: 37 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 4 2 | | 4 2 | 1 1 | +-----+-----+ count: 36 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 1 1 | | 4 2 | 1 1 | +-----+-----+ count: 30 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 1 2 | | 4 2 | 3 1 | +-----+-----+ count: 28 +-----+-----+ | 1 4 | 2 3 | | 2 3 | 1 4 | +-----+-----+ | 3 1 | 4 1 | | 4 2 | 1 1 | +-----+-----+ count: 25
次に、4x4の空き8マス(11条件)問題。 前回は解けなかったサイズの問題も解けた。
board = """ _ _ _ 1 _ 1 2 3 _ 4 1 _ 1 2 _ _ """ sudoku = Sudoku(board,2,2) qc = grover_sudoku(sudoku, mmax=1) run_grover_sudoku(sudoku, qc, backend)
-- sudoku problem -- +-----+-----+ | _ _ | _ 1 | | _ 1 | 2 3 | +-----+-----+ | _ 4 | 1 _ | | 1 2 | _ _ | +-----+-----+ -- answers -- +-----+-----+ | 2 3 | 4 1 | | 4 1 | 2 3 | +-----+-----+ | 3 4 | 1 2 | | 1 2 | 3 4 | +-----+-----+ count: 915 +-----+-----+ | 4 3 | 4 1 | | 4 1 | 2 3 | +-----+-----+ | 3 4 | 1 2 | | 1 2 | 4 4 | +-----+-----+ count: 25 +-----+-----+ | 4 3 | 4 1 | | 4 1 | 2 3 | +-----+-----+ | 3 4 | 1 2 | | 1 2 | 3 4 | +-----+-----+ count: 24 +-----+-----+ | 3 3 | 4 1 | | 4 1 | 2 3 | +-----+-----+ | 3 4 | 1 2 | | 1 2 | 3 4 | +-----+-----+ count: 23 +-----+-----+ | 3 3 | 4 1 | | 4 1 | 2 3 | +-----+-----+ | 3 4 | 1 2 | | 1 2 | 4 4 | +-----+-----+ count: 21 +-----+-----+ | 2 3 | 4 1 | | 4 1 | 2 3 | +-----+-----+ | 3 4 | 1 2 | | 1 2 | 4 4 | +-----+-----+ count: 16
続いて、6x6の空き6マス(8条件)問題。

board = """ _ 2 5 3 1 6 _ _ 6 5 2 4 _ _ _ 2 5 3 2 5 3 4 6 1 3 6 2 1 4 5 5 4 1 6 3 2 """ sudoku = Sudoku(board,2,3) qc = grover_sudoku(sudoku, mmax=1) run_grover_sudoku(sudoku, qc, backend)
-- sudoku problem -- +-------+-------+ | _ 2 5 | 3 1 6 | | _ _ 6 | 5 2 4 | +-------+-------+ | _ _ _ | 2 5 3 | | 2 5 3 | 4 6 1 | +-------+-------+ | 3 6 2 | 1 4 5 | | 5 4 1 | 6 3 2 | +-------+-------+ -- answers -- +-------+-------+ | 4 2 5 | 3 1 6 | | 1 3 6 | 5 2 4 | +-------+-------+ | 6 1 4 | 2 5 3 | | 2 5 3 | 4 6 1 | +-------+-------+ | 3 6 2 | 1 4 5 | | 5 4 1 | 6 3 2 | +-------+-------+ count: 926 +-------+-------+ | 4 2 5 | 3 1 6 | | 1 1 6 | 5 2 4 | +-------+-------+ | 4 1 4 | 2 5 3 | | 2 5 3 | 4 6 1 | +-------+-------+ | 3 6 2 | 1 4 5 | | 5 4 1 | 6 3 2 | +-------+-------+ count: 23 +-------+-------+ | 4 2 5 | 3 1 6 | | 1 3 6 | 5 2 4 | +-------+-------+ | 4 1 4 | 2 5 3 | | 2 5 3 | 4 6 1 | +-------+-------+ | 3 6 2 | 1 4 5 | | 5 4 1 | 6 3 2 | +-------+-------+ count: 22 +-------+-------+ | 4 2 5 | 3 1 6 | | 1 1 6 | 5 2 4 | +-------+-------+ | 1 1 4 | 2 5 3 | | 2 5 3 | 4 6 1 | +-------+-------+ | 3 6 2 | 1 4 5 | | 5 4 1 | 6 3 2 | +-------+-------+ count: 22 +-------+-------+ | 4 2 5 | 3 1 6 | | 1 1 6 | 5 2 4 | +-------+-------+ | 6 1 4 | 2 5 3 | | 2 5 3 | 4 6 1 | +-------+-------+ | 3 6 2 | 1 4 5 | | 5 4 1 | 6 3 2 | +-------+-------+ count: 16 +-------+-------+ | 4 2 5 | 3 1 6 | | 1 3 6 | 5 2 4 | +-------+-------+ | 1 1 4 | 2 5 3 | | 2 5 3 | 4 6 1 | +-------+-------+ | 3 6 2 | 1 4 5 | | 5 4 1 | 6 3 2 | +-------+-------+ count: 15
最後に、9x9の空き5マス(7条件)問題。 空きマスに入らないことが確定している数字(今回なら1とか)を除いて数字を8種類にして、 入力に必要な量子ビットを節約することもできると思うけど、今回はそのまま機械的に実行。

board = """ 4 3 5 7 8 6 9 2 1 1 9 7 4 2 3 8 5 6 6 2 8 _ 1 5 7 4 3 8 1 _ _ _ 2 6 7 4 5 7 2 _ 6 4 1 9 8 9 6 4 1 7 8 2 3 5 7 5 9 6 3 1 4 8 2 3 8 6 2 4 7 5 1 9 2 4 1 8 5 9 3 6 7 """ sudoku = Sudoku(board,3,3) qc = grover_sudoku(sudoku, mmax=1) run_grover_sudoku(sudoku, qc, backend)
-- sudoku problem -- +-------+-------+-------+ | 4 3 5 | 7 8 6 | 9 2 1 | | 1 9 7 | 4 2 3 | 8 5 6 | | 6 2 8 | _ 1 5 | 7 4 3 | +-------+-------+-------+ | 8 1 _ | _ _ 2 | 6 7 4 | | 5 7 2 | _ 6 4 | 1 9 8 | | 9 6 4 | 1 7 8 | 2 3 5 | +-------+-------+-------+ | 7 5 9 | 6 3 1 | 4 8 2 | | 3 8 6 | 2 4 7 | 5 1 9 | | 2 4 1 | 8 5 9 | 3 6 7 | +-------+-------+-------+ -- answers -- +-------+-------+-------+ | 4 3 5 | 7 8 6 | 9 2 1 | | 1 9 7 | 4 2 3 | 8 5 6 | | 6 2 8 | 9 1 5 | 7 4 3 | +-------+-------+-------+ | 8 1 3 | 5 9 2 | 6 7 4 | | 5 7 2 | 3 6 4 | 1 9 8 | | 9 6 4 | 1 7 8 | 2 3 5 | +-------+-------+-------+ | 7 5 9 | 6 3 1 | 4 8 2 | | 3 8 6 | 2 4 7 | 5 1 9 | | 2 4 1 | 8 5 9 | 3 6 7 | +-------+-------+-------+ count: 941 +-------+-------+-------+ | 4 3 5 | 7 8 6 | 9 2 1 | | 1 9 7 | 4 2 3 | 8 5 6 | | 6 2 8 | 9 1 5 | 7 4 3 | +-------+-------+-------+ | 8 1 3 | 3 9 2 | 6 7 4 | | 5 7 2 | 3 6 4 | 1 9 8 | | 9 6 4 | 1 7 8 | 2 3 5 | +-------+-------+-------+ | 7 5 9 | 6 3 1 | 4 8 2 | | 3 8 6 | 2 4 7 | 5 1 9 | | 2 4 1 | 8 5 9 | 3 6 7 | +-------+-------+-------+ count: 47 +-------+-------+-------+ | 4 3 5 | 7 8 6 | 9 2 1 | | 1 9 7 | 4 2 3 | 8 5 6 | | 6 2 8 | 9 1 5 | 7 4 3 | +-------+-------+-------+ | 8 1 3 | 9 9 2 | 6 7 4 | | 5 7 2 | 3 6 4 | 1 9 8 | | 9 6 4 | 1 7 8 | 2 3 5 | +-------+-------+-------+ | 7 5 9 | 6 3 1 | 4 8 2 | | 3 8 6 | 2 4 7 | 5 1 9 | | 2 4 1 | 8 5 9 | 3 6 7 | +-------+-------+-------+ count: 36
ということで、数独の問題を量子コンピュータ(のシミュレータ)で解くことができた!と(一応)いってもよいのではないだろううか。 9x9でも条件数が少ないと計算は軽いが、空きマスが増えると条件数がぐぐぐと増えるので(変数用に必要な量子レジスタも増える)、 通常の問題はおとなしくソルバを使おう。
nビット整数の任意の組み合わせに対応する初期状態を作る
Groverのアルゴリズムの初期化用に、nビット整数の任意の組み合わせに対応する初期状態を作る。
例えば、3量子ビットに対して{001,011,100,101,110}などの組み合わせを与えたときに、 その状態(この場合5状態)の同じ重みで同位相の重ね合わせ状態を作る。 とりあえずあまり効率などは考えずに機械的に作る方針。
量子ビットの初期化
前にやったものの一般化を考える。
まず、最上位ビットが0になる状態と1になる状態とに分ける。 {001,011,100,101,110}の場合、下記に分けられる。
- 最上位が0の状態:{001,011}の2状態
- 最上位が1の状態:{100,101,110}の3状態
この状態数に合う重みで重ね合わせるように、最上位の量子ビットをy軸周りに回転させる。 $ y $軸周りの回転$ R _ y(\theta) $ゲートは、
$$
%\require{physics}
\begin{align*}
R_y(\theta) \ket{0} &=
\cos \frac{\theta}{2} \ket{0} +
\sin \frac{\theta}{2} \ket{1}
\end{align*}
$$
なので、 今回の場合は、$ \cos(\theta/2) = \sqrt{2/5}, \sin(\theta/2) = \sqrt{3/5} $となる$ \theta $で回転させる。
その後、分けたそれぞれに対して、上位から第2ビットが0になる状態と1になる状態とに分ける。 {001,011,100,101,110}の場合、下記に分けられる。
- 最上位が0の状態:{001,011}の2状態
- 上位から第2ビットが0の状態:{001}の1状態
- 上位から第2ビットが1の状態:{011}の1状態
- 最上位が1の状態:{100,101,110}の3状態
- 上位から第2ビットが0の状態:{100,101}の2状態
- 上位から第2ビットが1の状態:{110}の1状態
最上位のビットを制御(または反転制御)ビットとした制御y回転ゲートを使って、 上位から第2ビットに応じて回転して分けていく。 1:1の場合は制御アダマールゲートでもよいけど(多分)、 ここでは簡単のため場合分けせずに制御$ R _ y(\pi/2) $ゲートとして扱う。 1:0の場合(上位から第2ビットが0のみ)のときには分けずに(または制御$ R _ y(0) $ゲート=恒等ゲート$ I $)次のビットに進み、 0:1の場合(上位から第2ビットが1のみ)のときには制御Xゲート(または制御$ R _ y(\pi) $ゲート)で分けて次のビットに進む。
上位から第3ビットおよびそれ以降についても同様に、制御制御y回転ゲートを使って分けていく。
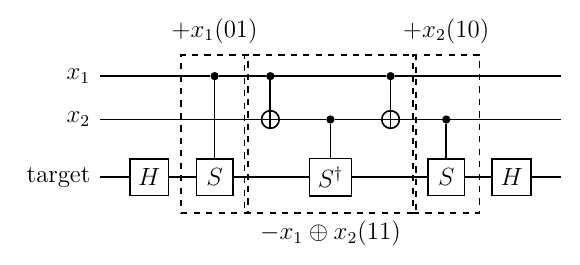
まとめると、{001,011,100,101,110,111}の場合、 $ \cos(\theta _ {i,j}/2) = \sqrt{i/(i+j)} $、 つまり $ \cos(\theta _ {2,1}/2) = \sqrt{2/3} $、 $ \cos(\theta _ {2,1}/2) = \sqrt{2/3} $、 $ \theta _ {1,1} = \pi/2 $、 $ \theta _ {1,0} = 0 $、 $ \theta _ {0,1} = \pi $ を使って、下記のようになる。 分岐の順が入れ替わらなければ、各y回転の順序は入れ替わってもよい(はず)。 つまり、1XX, 0XX, 00X, 01X, 11X, 10Xの順で回転してもよいし、 0XX, 00X, 01X, 1XX, 11X, 10Xの順で回転してもよい(多分)。 下図は前者に対応、実装は後者で行う。

制御制御回転yゲートは、 制御ビットがグレイコード順になるように適用すると、 反転制御ビットのためのXゲートの数が多少減る(他にもっと減らせるところはありそうな気もするけど)。 少し整理して、下記のようにしてもよい。

なお、$ XYX=-Y $なので$ XR _ y(\theta)X=R _ y ^ \dagger(\theta) $であることを利用して、 マルチ制御y回転ゲートは、マルチ制御Xゲートを使うと次のように構成できる。

また、$ Y=SXS ^ \dagger $、$ X=HZH $ なので $ Y=(SH)Z(SH) ^ \dagger $であり、 $ P(\theta)=e ^ {i\theta/2}R _ z(\theta) $で $ (SH)P(\theta)(SH) ^ \dagger = e ^ {i\theta/2}R _ y(\theta) $であることを利用して、 位相因子$ e ^ {i\theta/2} $を制御ビット側で処理して、 下記のようにマルチ制御位相ゲートを使って構成してもよい。

実装
Qiskit(v1.2.2)で実装する。
マルチ制御y回転ゲート
まず、マルチ制御y回転ゲートを作って確認する。 マルチ制御ゲートの深さ?が一つ少なく済むので、位相ゲートを使う方を採用する。
また、2進整数を入力して、それに応じた制御ビットを構成するようにする。 例えば、100なら下2桁のビットを反転制御ビットにし、最上位を通常の制御ビットにする、など。
import numpy as np from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister from qiskit.quantum_info import Statevector from qiskit_aer import AerSimulator from qiskit import transpile from qiskit.visualization import plot_histogram def multi_ctrl_ry(bctrl, theta, to_gate=True): nctrl = len(bctrl) qrc = QuantumRegister(nctrl,"ctrl") qrt = QuantumRegister(1,"tgt") qc = QuantumCircuit(qrc, qrt) qc.sdg(qrt) qc.h(qrt) for i,b in enumerate(reversed(bctrl)): if b == "0": qc.x(qrc[i]) qc.mcp(theta,qrc,qrt) # multi-contorolled phase gate qc.mcp(-theta/2, qrc[:-1], qrc[-1]) # phase correction for i,b in enumerate(reversed(bctrl)): if b == "0": qc.x(qrc[i]) qc.h(qrt) qc.s(qrt) return qc.to_gate(label=f"mcry{bctrl}\n{theta:0.3}") if to_gate else qc bctrl = "100" theta = 3*np.pi/4 multi_ctrl_ry(bctrl, theta, to_gate=False).draw(output='mpl')

qrc = QuantumRegister(len(bctrl),"ctrl") qrt = QuantumRegister(1,"tgt") qc = QuantumCircuit(qrc, qrt) qc.h(qrc) qc.append(multi_ctrl_ry(bctrl, theta), qrc[:]+qrt[:]) state = Statevector.from_instruction(qc) state.draw(output="qsphere")

指定した001状態(右側の3ビット)だけ、標的ビット(左端のビット)が0状態および1状態の重ね合わせになっている(|0 100>状態と|1 100>状態)。 また、$ 3\pi/4 $回転させているので、|0 100>状態の振幅より|1 100>状態の振幅が大きく、 |0 100>状態からのy回転なので同位相となっている。
初期化ゲート
内部関数devideを再帰的に呼び出すように実装している。
def cands_init(qbits, cands, to_gate=True): qc = QuantumCircuit(qbits) nbit = len(qbits) nprev = len(cands) def devide(key, lst): if not lst: return ntot = len(lst) nb = len(key) k0 = key + "0" k1 = key + "1" l0 = list(filter(lambda x: x.startswith(k0), lst)) l1 = list(filter(lambda x: x.startswith(k1), lst)) th = 2 * np.acos(np.sqrt(len(l0)/ntot)) if nb == 0: qc.ry(th, qbits[-1]) elif nb == 1: if key == "0": qc.x(qbits[-1]) qc.cry(th, qbits[-1], qbits[-2]) if key == "0": qc.x(qbits[-1]) else: qc.append(multi_ctrl_ry(key, th), qbits[-nb:]+qbits[-(nb+1):-nb]) if nb < nbit-1: devide(k0, l0) devide(k1, l1) devide("", cands) return qc.to_gate(label=r"$U_i$") if to_gate else qc # test nbit = 3 cands=["001","011","100","101","110"] # draw circuit qr = QuantumRegister(nbit,"q") qc = cands_init(qr, cands, to_gate=False) qc.draw(output='mpl')

# draw state vector state = Statevector.from_instruction(qc) state.draw(output="qsphere")

cr = ClassicalRegister(nbit,"c") qc.add_register(cr) qc.measure(qr, cr) backend = AerSimulator() tqc = transpile(qc, backend) job = backend.run(tqc, shots=8192) rst = job.result() counts = rst.get_counts() # plot plot_histogram(counts)

ということで、nビット整数の任意の組み合わせに対応する初期状態を作ることができた。
グレイコードを使ったマルチ制御ゲートなどのメモ その2
$ m $個の条件のANDが成立する場合に標的ビットに作用させるようなゲートを、 1つの補助ビットを使って構成する方法をまとめる。
単純には、条件の数だけ補助量子ビットを用意して、 最後にすべての補助量子ビットのANDを取るようなマルチ制御ゲートを適用させれば構成できる(uncomputationは省略)。

ただ、これだと条件数が増えるたびに必要な量子ビット数が増え、 すぐに計算ができなくなってしまう(特にシミュレータで)。 ということで、補助量子ビットは1つだけ使って同様のことができるゲートを構成しよう、という話 *1。
前回を応用して、 グレイコードを使って?構成する。
おさらい
前回のおさらいを 今回の記号に合わせて行う。
論理式$ Q _ 1,Q _ 2,\cdots,Q _ m $に対応する論理値$ f _ {Q _ i}(x) $が$ f _ {Q _ i}=0,1 $の値をとるとき、 下記が成立する。
$$
\require{physics}
\begin{align*}
2^{m-1} f_{Q_1} f_{Q_2} \cdots f_{Q_m}
=&
\sum_{r=1}^m \qty(-1)^{r-1}
\sum_{0 < l_1 < l_2 < \cdots < l_r < n+1}
f_{Q_{l_1}} \oplus f_{Q_{l_2}} \oplus \cdots \oplus f_{Q_{l_r}}
\\
=&
f_{Q_1} + \cdots + f_{Q_m} \\
& - f_{Q_1} \oplus f_{Q_2} - f_{Q_1} \oplus f_{Q_3} - \cdots - f_{Q_{m-1}} \oplus f_{Q_m} \\
& + f_{Q_1} \oplus f_{Q_2} \oplus f_{Q_3} + \cdots + f_{Q_{m-2}} \oplus f_{Q_{m-1}} \oplus f_{Q_m} \\
& \cdots \\
& + \qty(-1)^m
f_{Q_1} \oplus f_{Q_2} \oplus \cdots \oplus f_{Q_m}
\end{align*}
$$
全論理値のANDを適当なユニタリ変換$ U $の肩に乗せると、 全条件が成立するときは$ f _ {Q _ 1} f _ {Q _ 2} \cdots f _ {Q _ m}=1 $で$ U ^ 1=U $が作用し、 そうでないときは少なくとも1つ$ f _ {Q _ i}=0 $なものがあるので$ f _ {Q _ 1} f _ {Q _ 2} \cdots f _ {Q _ m}=0 $となって$ U ^ 0=I $と恒等ゲートが作用するので、 目的のゲート$ U ^ {f _ {Q _ 1} f _ {Q _ 2} \cdots f _ {Q _ m}} $が作れる。
これは、
$$
\begin{align*}
U^{f_{Q_1} f_{Q_2} \cdots f_{Q_m}}
&=
{\underbrace{\qty(U^{2^{-m+1}})}_{=V}}
^{2^{m-1} f_{Q_1} f_{Q_2} \cdots f_{Q_m}} \\
&=
V^{f_{Q_1}} \cdots V^{f_{Q_m}}
V^{- f_{Q_1} \oplus f_{Q_2}} V^{- f_{Q_1} \oplus f_{Q_3}} \cdots V^{- f_{Q_{m-1}} \oplus f_{Q_m}}
V^{f_{Q_1} \oplus f_{Q_2} \oplus f_{Q_3}} \cdots V^{f_{Q_{m-1}} \oplus f_{Q_{m-1}} \oplus f_{Q_m}}
\cdots
V^{ \qty(-1)^m
f_{Q_1} \oplus f_{Q_2} \oplus \cdots \oplus f_{Q_m} }
\end{align*}
$$
となるので、 制御Vゲート $ V ^ {f _ {Q _ 1}}, {V ^ \dagger} ^ {f _ {Q _ 1} \oplus f _ {Q _ 2}}, \ldots $を、 対応する2ビット二進数がグレイコード順になるように(1つずつビット値が変化するように) 作用させればよい。
例
1条件の場合
$ V ^ {f _ {Q _ 1}} $は、 $ Q _ 1 $に対応する制御Xゲートを補助量子ビットに作用させ、 その補助量子ビットを制御ビットとした制御Vゲートを標的ビットに作用させればよい。

2条件の場合
$ V ^ {f _ {Q _ 1}} $は、1条件の場合と同様。
$ {V ^ \dagger} ^ {f _ {Q _ 1} \oplus f _ {Q _ 2}} $は、 $ Q _ 1, Q _ 2 $のそれぞれに対応する制御Xゲートを補助量子ビットに作用させ、 その補助量子ビットを制御ビットとした制御Vゲートを標的ビットに作用させればよい。 $ Q _ 1 $に対応する制御Xゲートは $ V ^ {f _ {Q _ 1}} $のためにすでに作用させているので、 新たに作用させるゲートは$ Q _ 2 $に対応する制御Xゲートのみで十分。
その後、もう一度 $ Q _ 1 $に対応する制御Xゲートを作用させると、 既に作用させた制御Xゲートとキャンセルするので、 補助量子ビットを制御ビットとした制御Vゲートを標的ビットに作用させることで $ V ^ {f _ {Q _ 2}} $の作用として働くようになる。
まとめると、下記の回路のように構成できる。

3条件の場合
2条件の場合と同様に、各条件に対応する制御ゲートを補助量子ビットに作用させて、 その補助量子ビットを制御ビットとした制御Vゲートを標的ビットに順次作用させればよい。

これは、 2条件の場合のゲートを2つ作り、 $ Q _ 3 $に対応する制御Xゲートと補助量子ビットを制御ビットとした制御Vゲート($ V ^ \dagger $)と を挟めば構成できる。
4条件以上の場合も、同様に構成できる。
実装
Qiskit(v1.2.2)で実装する。
条件に対応するゲートと、そのゲートが適用される量子ビットとの組(タプル)のリストをconditionsとして、
これと量子レジスタqregsを引数にして全条件のANDが成立するときに
標的ビットにXを作用させるようなゲートを作る。
上記のように、m条件のゲートは、m番目の条件$ Q _ m $に対応する制御Xゲートと補助量子ビットを制御ビットとした制御Vゲートとを、m-1条件のゲートで挟めば構成できる。 ということで、m条件のゲートを適用させる内部関数を作って、これを再帰的に適用することで全体のゲートを構成する。 補助量子ビットをきれいにするように、m番目の条件$ Q _ m $に対応する制御Xゲートを最後に追加する。
制御Xゲートは、標的ビット$ X=HZH $の関係を使って、制御Zゲートを構成してから標的ビットをHで挟むことで実現する。 Zゲートは$ Z=P(\pi) $なので$ Z ^ {1/2 ^ {m-1}} = P(\pi/2 ^ {m-1}) $となる。
import numpy as np from qiskit import QuantumCircuit, QuantumRegister from qiskit.quantum_info import Statevector def multi_and_ctrl_x(qregs, conditions, to_gate=True): # multi AND controlled X gate # qregs : list of quantum registers # conditions: list of tuple (gate which corresponds to each condition, quantum bit(s) to be applied the gate except for target bit) qra = QuantumRegister(1, 'anc') # register for ancilla bit qrt = QuantumRegister(1, 'tgt') # register for target bit qc=QuantumCircuit(*qregs,qra,qrt) mc = len(conditions) th = np.pi/(2**(mc-1)) def append_gates(m): if m == 1: qc.append(conditions[m-1][0], conditions[m-1][1]+qra[:]) qc.cp(th, qra, qrt) else: append_gates(m-1) qc.append(conditions[m-1][0], conditions[m-1][1]+qra[:]) qc.cp(-th, qra, qrt) append_gates(m-1) qc.h(qrt) append_gates(mc) qc.append(conditions[mc-1][0], conditions[mc-1][1]+qra[:]) qc.h(qrt) return qc.to_gate(label="multi-AND") if to_gate else qc
1ビット変数でのテスト
テストとして、条件 $ \qty(A \lor B) \land \qty(B \lor C) \land \qty(C \lor A) $ ( (A or B) and (B or C) and (C or A) 、つまりA,B,Cのうち2以上がTrueの場合にTrue) に対応するゲートを作る。
ちなみに、$ A \lor B = \neg \qty(\neg \qty(A \lor B)) = \neg \qty( \qty( \neg A) \land \qty(\neg B) ) $ (A or B = not (not (A or B) ) = not ( (not A) and (not B) ) )なので、 2変数ならXゲートとトフォリゲートで構成できる。 任意の論理式についても、上記のようにandに変換すれば、 今回作成したマルチAND制御Xゲートを使ってマルチOR制御ゲートが構成できる。
def or_ctrl_x(to_gate=True): # OR controlled X gate qri = QuantumRegister(2, 'x0') qrt = QuantumRegister(1, 'tgt') qc=QuantumCircuit(qri,qrt) qc.x(qri) qc.x(qrt) qc.mcx(qri,qrt) qc.x(qri) return qc.to_gate(label="OR") if to_gate else qc qregs = [ QuantumRegister(1,'A'), QuantumRegister(1,'B'), QuantumRegister(1,'C'), ] Uor = or_ctrl_x() conditions = [ (Uor, qregs[0][:]+qregs[1][:]), (Uor, qregs[1][:]+qregs[2][:]), (Uor, qregs[2][:]+qregs[0][:]), ] multi_and_ctrl_x(qregs, conditions, to_gate=False).draw(output='mpl')

qra = QuantumRegister(1, 'anc') # register for ancilla bit qrt = QuantumRegister(1, 'tgt') # register for target bit qc=QuantumCircuit(*qregs,qra,qrt) qbs =[] for qr in qregs: qbs += qr[:] # Initialization qc.h(qbs) qc.append(multi_and_ctrl_x(qregs, conditions), qbs+qra[:]+qrt[:]) # draw statevector state = Statevector.from_instruction(qc) state.draw(output="qsphere")

ということで、A,B,C (右側の3ビット)のうち2以上が1の場合に標的ビット(一番左のビット)を反転させて1にしていることが確認できる。
2ビット変数でのテスト
2ビット変数についてもテスト。 4つの変数$ v _ 0, v _ 1, v _ 2, v _ 3 $がすべて異なるという下記の条件(6条件)を満たすゲートを作る。
$$
\bigwedge _ {0 \leq i < j < 4} \qty( v _ i \neq v _ j )
$$
2数が異なることを検出するゲートneqは、前に作ったものを流用する。
def neq(n, to_gate=True): # non-equality-conditional X gate with n-controll bit(s): # quantum gate which applies X-gate to the target qubit only when a != b, where a and b is n-bit variables qra = QuantumRegister(n, 'a') # register for 1st n-bit variable a qrb = QuantumRegister(n, 'b') # register for 2nd n-bit variable b qrt = QuantumRegister(1, 'tgt') # register for target bit qc=QuantumCircuit(qra,qrb,qrt) qc.x(qrb) for x in range(2**n): cb = [] for i,b in enumerate(format(x, f'0{n}b')[::-1]): if b == "1": cb.append(i) elif b == "0": cb.append(i+n) qc.mcx(cb,qrt) qc.x(qrb) qc.x(qrt) return qc.to_gate(label=r"$N$") if to_gate else qc
import itertools nvar = 4 nbit = 2 Un = neq(nbit) qregs = [] for i in range(nvar): qregs.append(QuantumRegister(nbit, f"v{i}")) conditions = [] for i,j in itertools.combinations(range(nvar), 2): conditions.append((Un, qregs[i][:]+qregs[j][:])) qra = QuantumRegister(1, 'anc') # register for ancilla bit qrt = QuantumRegister(1, 'tgt') # register for target bit qc=QuantumCircuit(*qregs,qra,qrt) qbs =[] for qr in qregs: qbs += qr[:] # Initialization qc.h(qbs) qc.append(multi_and_ctrl_x(qregs, conditions), qbs+qra[:]+qrt[:]) state = Statevector.from_instruction(qc) probs = state.probabilities_dict() eps = 1.0e-10 cnt = 0 for s, p in probs.items(): if s[0] == "1" and p > eps: cnt += 1 print(f"{cnt:2}. |{s[2:4]} {s[4:6]} {s[6:8]} {s[8:10]}> prob= {100*p:0.3}%")
1. |00 01 10 11> prob= 0.391% 2. |00 01 11 10> prob= 0.391% 3. |00 10 01 11> prob= 0.391% 4. |00 10 11 01> prob= 0.391% 5. |00 11 01 10> prob= 0.391% 6. |00 11 10 01> prob= 0.391% 7. |01 00 10 11> prob= 0.391% 8. |01 00 11 10> prob= 0.391% 9. |01 10 00 11> prob= 0.391% 10. |01 10 11 00> prob= 0.391% 11. |01 11 00 10> prob= 0.391% 12. |01 11 10 00> prob= 0.391% 13. |10 00 01 11> prob= 0.391% 14. |10 00 11 01> prob= 0.391% 15. |10 01 00 11> prob= 0.391% 16. |10 01 11 00> prob= 0.391% 17. |10 11 00 01> prob= 0.391% 18. |10 11 01 00> prob= 0.391% 19. |11 00 01 10> prob= 0.391% 20. |11 00 10 01> prob= 0.391% 21. |11 01 00 10> prob= 0.391% 22. |11 01 10 00> prob= 0.391% 23. |11 10 00 01> prob= 0.391% 24. |11 10 01 00> prob= 0.391%
ということで、標的ビット(一番左のビット)が反転されて1になっている状態を抽出すると、 4つの変数$ v _ 0, v _ 1, v _ 2, v _ 3 $がすべて異なっていることが確認できる。
*1:その代わりゲート数は増えるけど、まあ、実機で計算することはどのみち当面考えていないからOK
グレイコードを使ったマルチ制御ゲートなどのメモ
制御ビットが$ n $個ある場合のマルチ制御ゲートを(制御ビットが1個の制御ゲートを使って)構成する方法をまとめる。
制御ビット$ x _ 1,x _ 2,\cdots,x _ n $が$ x _ i=0,1 $の値をとるとき、
$$
\require{physics}
\begin{align*}
2^{n-1} x_1 x_2 \cdots x_n
=&
\sum_{r=1}^n \qty(-1)^{r-1}
\sum_{0 < l_1 < l_2 < \cdots < l_r < n+1}
x_{l_1} \oplus x_{l_2} \oplus \cdots \oplus x_{l_r}
\\
=&
x_1 + \cdots + x_{n} \\
& - x_1 \oplus x_2 - x_1 \oplus x_3 - \cdots - x_{n-1} \oplus x_n \\
& + x_1 \oplus x_2 \oplus x_3 + \cdots x_{n-2} \oplus x_{n-1} \oplus x_n \\
& \cdots \\
& + \qty(-1)^n
x_1 \oplus x_2 \oplus \cdots \oplus x_n
\end{align*}
$$
つまり、制御ビットを少なくとも1つ以上選ぶすべての選択について、 選んだ制御ビットに応じた符号(奇数個なら+、偶数個なら-)をかけて足し合わせると、 全制御ビットのAND(に$ 2 ^ {n-1} $を乗じたもの)になる。 なお、このときの加算および減算は、通常の整数としての加減算。
全制御ビットのANDを$ U $の肩に乗せると、 全制御ビットのANDが成立するときは$ x _ 1 x _ 2 \cdots x _ n=1 $で$ U ^ 1=U $が作用し、 そうでないときは少なくとも1つ$ x _ i=0 $なものがあるので$ x _ 1 x _ 2 \cdots x _ n=0 $となって$ U ^ 0=I $と恒等ゲートが作用するので マルチ制御Uゲート$ U ^ {x _ 1 x _ 2 \cdots x _ n} $が作れる。
これは、
$$
\begin{align*}
U^{x_1 x_2 \cdots x_n}
&=
{\underbrace{\qty(U^{2^{-n+1}})}_{=V}}
^{2^{n-1} x_1 x_2 \cdots x_n} \\
&=
V^{2^{n-1} x_1 x_2 \cdots x_n} \\
&=
V^{
\sum_{r=1}^n \qty(-1)^{r-1}
\sum_{0 < l_1 < l_2 < \cdots < l_r < n+1}
x_{l_1} \oplus x_{l_2} \oplus \cdots \oplus x_{l_r}
} \\
&=
\prod_{r=1}^n
\prod_{0 < l_1 < l_2 < \cdots < l_r < n+1}
V^{
\qty(-1)^{r-1}x_{l_1} \oplus x_{l_2} \oplus \cdots \oplus x_{l_r}
} \\
&=
V^{x_1} \cdots V^{x_{n}}
V^{- x_1 \oplus x_2} V^{- x_1 \oplus x_3} \cdots V^{- x_{n-1} \oplus x_n}
V^{x_1 \oplus x_2 \oplus x_3} \cdots V^{x_{n-2} \oplus x_{n-1} \oplus x_n}
\cdots
V^{ \qty(-1)^n
x_1 \oplus x_2 \oplus \cdots \oplus x_n }
\end{align*}
$$
となるので、 制御ビットを少なくとも1つ以上選ぶすべての選択について、 選んだビットを制御ビットとして制御ユニタリゲートを作用させる(奇数個なら$ V=U ^ {2 ^ {-n+1}} $、偶数個なら$ V ^ {-1}=V ^ \dagger $)とよい。 XORは単純に制御Xゲートを順に作用させると構成できる。 制御ビットの選択は、nビット二進数の各ビットを各制御ビットに対応させて、 対応するビットが1のときに選択し、0のときに選択しないようにすればOK。 このとき、ハミング距離が1ずつ変わるようにグレイコードの順で数え上げると、 うまい具合にキャンセルが生じるので都合がよい。
帰納法での証明
$$
\begin{align*}
2^{n-1} x_1 x_2 \cdots x_n
&=
\sum_{r=1}^n \qty(-1)^{r-1}
\sum_{0 < l_1 < l_2 < \cdots < l_r < n+1}
x_{l_1} \oplus x_{l_2} \oplus \cdots \oplus x_{l_r}
\end{align*}
$$
を帰納法で証明する。
n=2のとき
$$
\begin{align*}
2 x_1 x_2
&=
x_1 + x_2 - x_1 \oplus x_2
\end{align*}
$$
を示せばよい。
$ x _ 1=x _ 2=0 $の場合、両辺とも0になる。 $ x _ 1, x _ 2 $の一方のみが1の場合、 左辺は0、 右辺についても、単一ビットに対応する項のうち1つのみが1で、XORに対応する項も1なので、キャンセルして0になる。 $ x _ 1=x _ 2=1 $の場合、 左辺は2、 右辺についても、単一ビットに対応する項の両方が1で、XORに対応する項は0なので、あわせて2になる。
つまり、$ x _ i=0,1 $の値をとるとき、上記は成立する。
論理式$ A,B $について、真偽値を0,1で表現するときも同様に成立する。
$$
\begin{align*}
2 A B
&=
A + B - A \oplus B
\end{align*}
$$
n=kのとき成立するとして、n=k+1のとき
$ n=k $のとき、
$$
\begin{align*}
2^{k-1} x_1 x_2 \cdots x_k
&=
\sum_{r=1}^k \qty(-1)^{r-1}
\sum_{0 < l_1 < l_2 < \cdots < l_r < k+1}
x_{l_1} \oplus x_{l_2} \oplus \cdots \oplus x_{l_r}
\end{align*}
$$
が成立すると仮定する。
このとき、右辺の各項$ x _ {l _ 1} \oplus x _ {l _ 2} \oplus \cdots \oplus x _ {l _ r} $も0,1いずれかの値を取る論理式なので、 $ x _ {k+1} $とのANDをとって2倍すると、上記$ A,B $についての式と同様にして以下が成立する。
$$
\begin{align*}
2
\underbrace{x_{l_1} \oplus x_{l_2} \oplus \cdots \oplus x_{l_r}}_{A}
\cdot \underbrace{x_{k+1}}_{B}
&=
\underbrace{x_{l_1} \oplus x_{l_2} \oplus \cdots \oplus x_{l_r}}_{A}
+\underbrace{x_{k+1}}_{B}
-\underbrace{x_{l_1} \oplus x_{l_2} \oplus \cdots \oplus x_{l_r}}_{A}
\oplus \underbrace{x_{k+1}}_{B}
\end{align*}
$$
これを使うと、$ x _ 1 $から$ x _ {k+1} $までANDを取って$ 2 ^ k $倍したものは、 上記の$ n=k $についての式も使って、
$$
\begin{align*}
2^{k} x_1 x_2 \cdots x_k x_{k+1}
=&
\sum_{r=1}^k \qty(-1)^{r-1}
\sum_{0 < l_1 < l_2 < \cdots < l_r < k+1}
2 \qty[
x_{l_1} \oplus x_{l_2} \oplus \cdots \oplus x_{l_r}
] \cdot x_{k+1} \\
=&
\sum_{r=1}^k \qty(-1)^{r-1}
\sum_{0 < l_1 < l_2 < \cdots < l_r < k+1}
\qty[
x_{l_1} \oplus x_{l_2} \oplus \cdots \oplus x_{l_r}
+x_{k+1}
-x_{l_1} \oplus x_{l_2} \oplus \cdots \oplus x_{l_r}
\oplus x_{k+1}
] \\
=&
\sum_{0 < l_1 < k+1} x_{l_1}
+
\underbrace{
\sum_{r=1}^k \qty(-1)^{r-1} \sum_{0 < l_1 < l_2 < \cdots < l_r < k+1}
}_{=1} +
x_{k+1}
& \mbox{(1次の項)} \\
&
-\sum_{0 < l_1 < l_2 < k+1} x_{l_1} \oplus x_{l_2}
-\sum_{0 < l_1 < k+1} x_{l_1} \oplus x_{k+1}
& \mbox{(2次の項)} \\
&
+\sum_{0 < l_1 < l_2 < l_3 < k+1} x_{l_1} \oplus x_{l_2} \oplus x_{l_3}
+\sum_{0 < l_1 < l_2 < k+1} x_{l_1} \oplus x_{l_2} \oplus x_{k+1}
& \mbox{(3次の項)} \\
& + \cdots \\
&
+\qty(-1)^{r-1}\sum_{0 < l_1 < \cdots < l_r < k+1}
\overbrace{x_{l_1} \oplus \cdots \oplus x_{l_r}}^{\mbox{$r$次}}
-\qty(-1)^{r-2}\sum_{0 < l_1 < \cdots < l_{r-1} < k+1}
\overbrace{x_{l_1} \oplus \cdots \oplus x_{l_{r-1}}}^{\mbox{$r-1$次}}
\oplus x_{k+1}
& \mbox{($r$次の項)} \\
& + \cdots \\
&
-\qty(-1)^{k-1} x_{l_1} \oplus \cdots \oplus x_{k} \oplus x_{k+1}
& \mbox{($k+1$次の項)} \\
=&
\sum_{r=1}^{k+1} \qty(-1)^{r-1}
\sum_{0 < l_1 < l_2 < \cdots < l_r < k+2}
x_{l_1} \oplus x_{l_2} \oplus \cdots \oplus x_{l_r}
\end{align*}
$$
ここで、1次の$ x _ {k+1} $の項の係数$ \sum _ {r=1} ^ k \qty(-1) ^ {r-1} \sum _ {0 < l _ 1 < l _ 2 < \cdots < l _ r < k+1} $について、 この総和の各項はk+1ビットの二進数に対応し($ r $は値が1となるビットの数、$ l _ 1,\ldots,l _ r $は値が1となるビットの位に対応)、 000…0に対応する項のみを除いて符号(奇数個なら+、偶数個なら-)をかけた上で総和を取っている。 000…0に対応する項(=-1)まで含めて総和を取ると全部キャンセルして0になるところ、 その項(=-1)のみが除かれているので、結局総和の値は1となる。
結論
このように、$ n=2 $の場合に成立し、 $ n=k $で成立すると仮定すると$ n=k+1 $の場合にも成立するので、 $ n>2 $で以下が成立する。
$$
\begin{align*}
2^{n-1} x_1 x_2 \cdots x_n
&=
\sum_{r=1}^n \qty(-1)^{r-1}
\sum_{0 < l_1 < l_2 < \cdots < l_r < n+1}
x_{l_1} \oplus x_{l_2} \oplus \cdots \oplus x_{l_r}
\end{align*}
$$
例
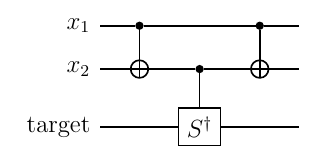
トフォリゲート
制御制御Xゲートを構成する。 n=2で、$ U=X $の場合に対応。 $ X=HZH $なので、制御制御Zゲートを作って、標的ビットをHで挟めばよい。
制御制御Zゲートは、 $ 2 x_1 x_2= x_1 + x_2 -x_1 x_2$ の関係と $Z^{1/2}=S$ を使って、
$$
\begin{align*}
Z^{x_1 x_2} &= S^{2 x_1 x_2} \\
&= S^{x_1 + x_2 -x_1 \oplus x_2} \\
&= S^{x_1} S^{x_2} {S^\dagger}^{x_1 \oplus x_2}
\end{align*}
$$
と書ける。
ということで、制御Sゲート $ S ^ {x _ 1}, S ^ {x _ 2}, {S ^ \dagger} ^ {x _ 1 \oplus x _ 2} $を順次作用させればよい。 この各ゲートは、2ビット二進数01,10,11にそれぞれ対応する。 制御ビットの状態を変えず、標的ビットには互いに可換な$ S,S ^ \dagger $が作用するので、 どのような順序で作用させてもよい。 ここでは、 対応する2ビット二進数がグレイコード順になるように(1つずつビット値が変化するように)、 01,11,10の順、すなわち $ S ^ {x _ 1}, {S ^ \dagger} ^ {x _ 1 \oplus x _ 2}, S ^ {x _ 2} $ の順に作用させる。
2ビット二進数11に対応する $ {S ^ \dagger} ^ {x _ 1 \oplus x _ 2} $は、 下記のように、
- 最高位ビットを標的ビットとし、1である他のビットを制御ビットとした制御$ X $ゲート
- 最高位ビットを制御ビットとした(単一)制御$ S $ゲート
で実現する。制御ビットの状態を戻すように、制御Sゲートの後にも同様に制御Xゲートを入れる。
以上をまとめると、制御Sゲートを使って、トフォリゲートは次のように書ける。
ところで、制御Sゲートは次のように書ける。
これを代入して、トフォリゲートは次のようにT(およびそのエルミート共役)、H、および制御Xで書ける*1

制御制御制御Uゲート
制御制御制御Uゲートを構成する。 n=3の場合に対応。 $ 4 x_1 x_2 x_3 = x_1 + x_2 + x_3 -x_1 x_2 -x_1 x_3 -x_2 x_3 +x_1 x_2 x_3 $ の関係と $U^{1/4}=V$を使って、
$$
\begin{align*}
U^{x_1 x_2 x_3} &= V^{4 x_1 x_2 x_3} \\
&= V^{
x_1 + x_2 + x_3
-x_1 \oplus x_2 -x_1 \oplus x_3 -x_2 \oplus x_3
+x_1 \oplus x_2 \oplus x_3
} \\
&= V^{x_1} V^{x_2} V^{x_3}
{V^\dagger}^{x_1 \oplus x_2}
{V^\dagger}^{x_1 \oplus x_3}
{V^\dagger}^{x_2 \oplus x_3}
V^{x_1 \oplus x_2 \oplus x_3}
\end{align*}
$$
と書ける。
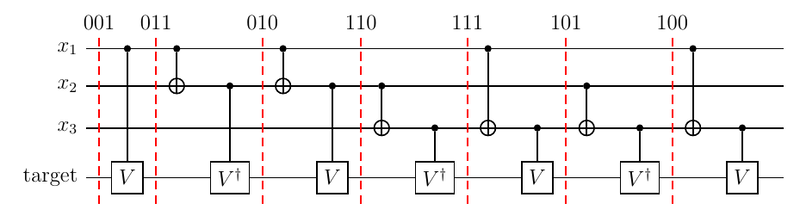
ということで、制御Vゲート $V ^ {x _ 1}, V ^ {x _ 2}, V ^ {x _ 3}, {V ^ \dagger} ^ {x _ 1 \oplus x _ 2}, {V ^ \dagger} ^ {x _ 1 \oplus x _ 3}, {V ^ \dagger} ^ {x _ 2 \oplus x _ 3}, V ^ {x _ 1 \oplus x _ 2 \oplus x _ 3}$ を順次作用させればよい。 この各ゲートは、3ビット二進数001, 010, 100, 011, 101, 110, 111にそれぞれ対応する。 制御ビットの状態を変えず、標的ビットには互いに可換な$ V,V ^ \dagger $が作用するので、 どのような順序で作用させてもよい。 ここでは、 対応する3ビット二進数がグレイコード順になるように、 001,011, 010,110, 111,101, 100 の順、すなわち $ V ^ {x _ 1}, {V ^ \dagger} ^ {x _ 1 \oplus x _ 2}, V ^ {x _ 2}, {V ^ \dagger} ^ {x _ 2 \oplus x _ 3}, V ^ {x _ 1 \oplus x _ 2 \oplus x _ 3}, {V ^ \dagger} ^ {x _ 1 \oplus x _ 3}, V ^ {x _ 3} $ の順に作用させる。
複数ビットが1であるような3ビット二進数110に対応する $ {S ^ \dagger} ^ {x _ 2 \oplus x _ 3} $などは、
- 最高位ビットを標的ビットとし、1である他のビットを制御ビットとした制御$ X $ゲート
- 最高位ビットを制御ビットとした(単一)制御$ V $ゲート
で実現する。制御ビットの状態を戻すように、制御Vゲートの後にも同様に制御Xゲートを入れる。
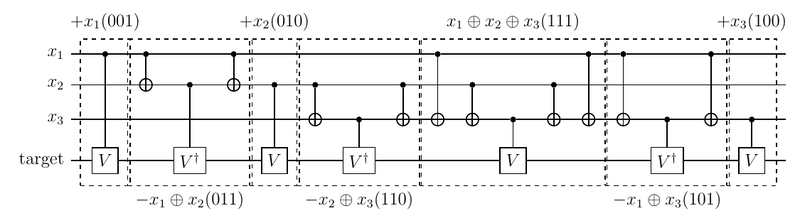
対応する3ビット二進数がグレイコード順になるように各ゲートを作用させているので、 となりあうゲートの間で共通する制御Xゲート(変化していないビットに対応する制御Xゲート)がキャンセルする。 これを使って整理すると下記のようになって、 この記事にあるように機械的に構成できるようになる。
*1:$ TT ^ \dagger=I $としたり、もう少し整理できる
制御U3ゲートなどのメモ
1ビット量子状態はブロッホ球の球面上の点で表される。 なので、一般の1ビット量子ゲート$ U _ 3 $は、ブロッホ球上のEuler回転であらわされる。 ということで、x,y,z軸周りの回転ゲート
$$
%\require{physics}
\begin{align*}
R_x \qty(\theta) &= \exp \qty(-i\frac{\theta}{2} X) &
&= \mqty[
\cos\qty(\theta/2) & -i\sin\qty(\theta/2) \\
-i\sin\qty(\theta/2) & \cos\qty(\theta/2) ] \\
R_y \qty(\theta) &= \exp \qty(-i\frac{\theta}{2} Y) &
&= \mqty[
\cos\qty(\theta/2) & -\sin\qty(\theta/2) \\
\sin\qty(\theta/2) & \cos\qty(\theta/2) ] \\
R_z \qty(\theta) &= \exp \qty(-i\frac{\theta}{2} Z) &
&= \mqty[e^{-i\theta/2} & 0 \\ 0 & e^{i\theta/2}]
\end{align*}
$$
を使って、
$$
\begin{align*}
U_3 \qty(\chi,\theta,\phi) &=
R_z \qty(\chi)
R_y \qty(\theta)
R_z \qty(\phi)
\end{align*}
$$
と書ける。
z軸周りの回転$ R _ z $と位相ゲート$ P $は次の関係があるので、
$$
\begin{align*}
R_z \qty(\theta) &= e^{-i\theta/2} \mqty[1 & 0 \\ 0 & e^{i\theta}]
= e^{-i\theta/2} P\qty(\theta)
\end{align*}
$$
次のように書いてもよい。 位相因子を省いて定義してもよい。
$$
\begin{align*}
U_3 \qty(\chi,\theta,\phi)
&=
e^{-i(\chi+\phi)/2}
P \qty(\chi)
R_y \qty(\theta)
P \qty(\phi) \\
&=
e^{-i(\chi+\phi)/2}
\mqty[
1 & 0 \\
0 & e^{i\chi} ]
\mqty[
\cos\qty(\theta/2) & -\sin\qty(\theta/2) \\
\sin\qty(\theta/2) & \cos\qty(\theta/2) ]
\mqty[
1 & 0 \\
0 & e^{i\phi} ] \\
&=
e^{-i(\chi+\phi)/2}
\mqty[
\cos\qty(\theta/2) & -e^{i\phi} \sin\qty(\theta/2) \\
e^{i\chi}\sin\qty(\theta/2) & e^{i(\phi+\chi)}\cos\qty(\theta/2) ]
\end{align*}
$$
これを制御U3ゲート化するときのもろもろをまとめる。
制御ゲート化
$ XYX=-Y, XZX=-Z $なので、
$$
\begin{align*}
XR_y(\theta)X &= R_y(-\theta)=R_y^\dagger(\theta) \\
XR_z(\theta)X &= R_z(-\theta)=R_z^\dagger(\theta) \\
XP(\theta)X &= e^{i\theta/2}XR_z(\theta)X
= e^{i\theta/2}R_z(-\theta)
= e^{i\theta}P(-\theta)
= e^{i\theta}P^\dagger(\theta)
\end{align*}
$$
となって、y,z軸周りの回転はXゲートで挟むと逆回転になる。 U3ゲートはEuler回転で表すとz回転-y回転-z回転なので、 間に挟まっているy回転がキャンセルされると1つのz回転にまとめられるようになる。
ということで、左のz回転と真ん中のy回転を2つに分けて、次のように構成すればよい。 - 制御ビットが0のとき、すなわち標的ビットにXゲートが作用しないときには回転がすべてキャンセルして恒等ゲート$ I $となる - 制御ビットが1のとき、すなわち標的ビットにXゲートが作用するときに回転がキャンセルせずにU3ゲートとなる
つまり、y回転は$ \kappa,\lambda $に分け、z回転は左右に2つあるので左側を$ \mu,\nu $に分けるとすると、
$$
\begin{align*}
I
&=
R_z \qty(\mu)
R_z \qty(\nu)
R_y \qty(\kappa)
R_y \qty(\lambda)
R_z \qty(\phi) \\
&=
R_z \qty(\mu+\nu)
R_y \qty(\kappa+\lambda)
R_z \qty(\phi)
\\
U_3 \qty(\chi,\theta,\phi)
&=
R_z \qty(\mu)
X
R_z \qty(\nu)
\underbrace{XX}_{=I}
R_y \qty(\kappa)
X
R_y \qty(\lambda)
R_z \qty(\phi) \\
&=
R_z \qty(\mu)
R_z \qty(-\nu)
R_y \qty(-\kappa)
R_y \qty(\lambda)
R_z \qty(\phi) \\
&=
R_z \qty(\mu-\nu)
R_y \qty(-\kappa+\lambda)
R_z \qty(\phi)
\end{align*}
$$
となればよい。
つまり、
$$
\begin{align*}
\mu+\nu &= -\phi \\
\kappa+\lambda &= 0 \\
\mu-\nu &= \chi \\
-\kappa+\lambda &= \theta
\end{align*}
$$
であればよく、これを解くと
$$
\begin{align*}
\mu &= \frac{-\phi+\chi}2 ,&
\nu &= -\frac{ \phi+\chi}2 ,&
\lambda &= \frac{\theta}2 ,&
\kappa &= -\frac{\theta}2
\end{align*}
$$
になるので、U3ゲートは次のように分解するとよい。
$$
\begin{align*}
U_3 \qty(\chi,\theta,\phi)
&=
R_z \qty(\frac{-\phi+\chi}2)
X
R_z \qty(-\frac{\phi+\chi}2)
R_y \qty(-\frac{\theta}2)
X
R_y \qty( \frac{\theta}2)
R_z \qty(\phi) \\
I
&=
R_z \qty(\frac{-\phi+\chi}2)
R_z \qty(-\frac{\phi+\chi}2)
R_y \qty(-\frac{\theta}2)
R_y \qty( \frac{\theta}2)
R_z \qty(\phi) \\
\end{align*}
$$

位相因子を除いてU3ゲートを$ U _ 3\qty(\chi,\theta,\phi) = P\qty(\chi) R _ y(\theta) P(\phi) $と定義している場合は、
$$
\begin{align*}
U_3 \qty(\chi,\theta,\phi)
&=
\exp \qty(i\frac{\phi+\chi}2)
P \qty(\frac{-\phi+\chi}2)
X
P \qty(-\frac{\phi+\chi}2)
R_y \qty(-\frac{\theta}2)
X
R_y \qty( \frac{\theta}2)
P \qty(\phi) \\
I
&=
P \qty(\frac{-\phi+\chi}2)
P \qty(-\frac{\phi+\chi}2)
R_y \qty(-\frac{\theta}2)
R_y \qty( \frac{\theta}2)
P \qty(\phi) \\
\end{align*}
$$
となり、Xゲートで挟むときに現れる位相因子を制御ビットに作用する位相ゲートで処理して、次のようになる。

z回転だけの場合、つまり位相ゲートの場合、 $ XP(\phi) ^ \dagger X = XP(-\phi) X =e ^ {-i\phi}P(\phi) $なので、 z回転を半分ずつに分けて次のように簡単に書ける (位相因子$ e ^ {-i\phi} $は制御ビットに位相ゲートをかけて処理)。

y回転だけの場合も同様に簡単化できる。 また、x回転だけの場合、 $ X=HZH $なので、$ R _ x=HR _ zH $となって、 制御z回転として構成した後に標的ビットをアダマールゲート$ H $で挟めばよい。
例
$ S=\sqrt{Z} $
$ S=\sqrt{Z}=P(\pi/2)=U _ 3(0,0,\pi/2) $を制御ゲート化する。 ここで、U3は位相ゲート$ P $を使って定義するものとする。
$ \phi=\pi/2, \theta=\chi=0 $なので、$ T=\sqrt{S}=P(\pi/4)=U _ 3(0,0,\pi/4) $を使って、次のようになる。

$ S $ゲートはz回転だけなので、下記のように構成してもよい。

$ X ^ {1/m} $
$ X ^ {1/m} $を制御ゲート化する。 U3は位相ゲート$ P $を使って定義するものとする。
$ X=HZH $なので、$ X ^ {1/m}=HZ ^ {1/m}H $となる。 $ Z ^ {1/m}=P(\pi/m)=U _ 3(0,0,\pi/m) $なので、 $ S $ゲートの場合と同じように制御ゲート化した後に、標的ビットを$ H $で挟めばよい。

これもz回転だけなので、下記のように構成してもよい。

$ R _ y(\alpha) $
$ R _ y(\alpha) $を制御ゲート化する。
$ \phi=\chi=0, \theta=\alpha $なので、次のようになる。

$ H $
アダマールゲート$ H $を制御ゲート化する。 $ \phi=\pi, \theta=\pi/4,\chi=0 $なので、次のようになる。

実装
Qiskit(v1.2.2)で実装(というか、確認)する。
$ S=\sqrt{Z} $
一般の場合の構成を使った構成で確認する。
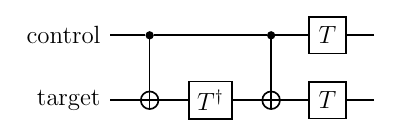
import numpy as np from qiskit import QuantumCircuit, QuantumRegister from qiskit.quantum_info import Statevector def ctrl_s(to_gate=True): qrc = QuantumRegister(1, 'ctrl') # register for control bit qrt = QuantumRegister(1, 'tgt') # register for target bit qc=QuantumCircuit(qrc,qrt) qc.s(qrt) qc.cx(qrc,qrt) qc.tdg(qrt) qc.cx(qrc,qrt) qc.t(qrc) qc.tdg(qrt) return qc.to_gate(label="ctrl-S") if to_gate else qc ctrl_s(to_gate=False).draw(output='mpl')

qrc = QuantumRegister(1, 'ctrl') # register for control bit qrt = QuantumRegister(1, 'tgt') # register for target bit qc=QuantumCircuit(qrc,qrt) # initialization (superposition) qc.h(qrc) qc.h(qrt) # draw statevector qc.append(ctrl_s(), qrc[:]+qrt[:]) state = Statevector.from_instruction(qc) state.draw(output="qsphere")

ということで、制御ビット(右側のビット)が1の場合に、Sゲートが効いている(標的ビットが1の場合に$ \pi/2 $だけ位相が進む)ことが確認できる。
$ X ^ {1/m} $
z回転のみの場合として簡単化した構成で確認する。
def ctrl_xm(m, to_gate=True): qrc = QuantumRegister(1, 'ctrl') # register for control bit qrt = QuantumRegister(1, 'tgt') # register for target bit qc=QuantumCircuit(qrc,qrt) pi2m = np.pi/2/m qc.h(qrt) qc.cx(qrc,qrt) qc.p(-pi2m, qrt) qc.cx(qrc,qrt) qc.p( pi2m, qrc) qc.p( pi2m, qrt) qc.h(qrt) return qc.to_gate(label="ctrl-X^(1/m)") if to_gate else qc ctrl_xm(4, to_gate=False).draw(output='mpl')

qrc = QuantumRegister(1, 'ctrl') # register for control bit qrt = QuantumRegister(1, 'tgt') # register for target bit qc=QuantumCircuit(qrc,qrt) # initialization (superposition) qc.h(qrc) xm4 = ctrl_xm(4) # draw statevector (before appllication ctrl-xm gate) state = Statevector.from_instruction(qc) state.draw(output="qsphere")

# draw statevector (after appllication 1 ctrl-xm gate) qc.append(xm4, qrc[:]+qrt[:]) state = Statevector.from_instruction(qc) state.draw(output="qsphere")

# draw statevector (after appllication 2 ctrl-xm gates) qc.append(xm4, qrc[:]+qrt[:]) state = Statevector.from_instruction(qc) state.draw(output="qsphere")

# draw statevector (after appllication 3 ctrl-xm gates) qc.append(xm4, qrc[:]+qrt[:]) state = Statevector.from_instruction(qc) state.draw(output="qsphere")

# draw statevector (after appllication 4 ctrl-xm gates) qc.append(xm4, qrc[:]+qrt[:]) state = Statevector.from_instruction(qc) state.draw(output="qsphere")

ということで、制御ビット(右側のビット)が0の場合には何もせず、 制御ビットが1の場合には4回かけて標的ビットを0状態から1状態にすることが確認できる。
4x4数独をGroverのアルゴリズムで解く
数独については、下記を参照。
9x9サイズの数独は大変なので、4x4サイズの数独を対象にする。 基本的には、前にやったものと同じ流れで解く*1。
例題
以下の問題を例題として解く。

方針
空きマスにそれぞれ2ビットの量子レジスタを割り当て、 各マスの数字を2進の量子状態で表現(1→|00>, 2→|01>, 3→|10>, 4→|11>)する。 すでに盤面に入っている数字から空きマスの状態の候補を絞り込んで、初期値とする。 絞り込んだ候補は以下。

候補が1個だけのもの(既に確定しているもの)もあるが、 4x4の場合これを埋めてしまうとほとんど自動的に解けてしまうので、 ここでは対応するレジスタの初期状態を1つだけの量子状態としてそのまま扱う。
一方、数独のルールによる要請(同じ行、列、ブロックに同じ数字が入らない)は、 オラクルで条件を満たすものを検索することで取り込む。
初期化
各マスの候補ごとの初期化は、以下のように行う。
| 候補(数値) | 候補(2ビット) | 初期化ゲート |
|---|---|---|
| {1} | {00} |  |
| {2} | {01} |  |
| {3} | {10} |  |
| {4} | {11} |  |
| {1,2} | {00,01} |  |
| {1,3} | {00,10} |  |
| {1,4} | {00,11} |  |
| {2,3} | {01,10} |  |
| {2,4} | {01,11} |  |
| {3,4} | {10,11} |  |
| {1,2,3} | {00,01,10} |  |
| {1,2,4} | {00,01,11} |  |
| {1,3,4} | {00,10,11} |  |
| {2,3,4} | {01,10,11} |  |
| {1,2,3,4} | {00,01,10,11} |  |







